
Why Most Experimentation Programs Plateau
And how to tell if your program is delivering impact


👋 Hey there, welcome (or welcome back)!
This newsletter isn’t entirely new but it is freshly rebooted. What started as a space for data science and analytics posts now has a much sharper focus:
How to scale experimentation into a high-impact, growth engine.
Since my time at Meta, Booking.com, and Canva, I’ve been helping APAC businesses do exactly that: building experimentation programs that don’t just run more tests or ship prettier dashboards, but deliver real strategic value.
If that’s something you’re working toward, you’re in the right place.
This phrase, “high-impact experimentation”, is central to what I do. But what does it actually mean?
In this first edition, I’ll share how I define it, how I measure it, and why most teams struggle to achieve it.
Why most teams fall short of high-impact experimentation

Early on, things feel good:
Tests are getting shipped.
A few big wins pop up.
Stakeholders lean in.
Then the vibe shifts:
Velocity drops.
Wins get smaller or harder to interpret.
The backlog grows, but nothing feels urgent.
The team’s still working hard. But impact? Unclear.
It all starts to feel… flat.

Why it happens: teams focus on the wrong things
When experimentation programs plateau, it’s rarely due to lack of interest or effort. It’s usually because teams are focusing on the wrong things or solving problems that aren’t actually theirs to solve (yet).
1. They focus on solutions, not problems
I get asked all the time about advanced experimentation techniques like CUPED adjustments, sequential testing, real-time pipelines. All great tools. All used by world-class teams at scale.
But what most people don’t see is the foundation those tools sit on:
A culture of innovation
Empowered cross-functional teams
Clear problem ownership
Executive sponsorship
Without that, adding complex techniques is like installing turbochargers in a car with no wheels.
Many frameworks out there—including some good ones—focus on maturity checklists: what tech stack you should have, how teams are structured, what features to build. That’s useful if you’re already scaling. But for most teams, these are solutions to the wrong problems.
High-impact experimentation starts with problems worth solving, not features worth building.
2. They struggle to communicate the right value to the right people
Even teams running genuinely good tests often struggle to win the support they need to grow. Why? Because they frame experimentation in their language, not their stakeholders’.
Experimenters talk about:
Improved decision quality
Avoided negative launches
Nuanced customer insights
Executives, meanwhile, are asking:
"Can this help us go faster with less risk?"
"Can this unblock our teams or priorities?"
"Can this scale my influence or align the org?"
High-impact programs don’t just generate value, they translate it.
That brings us to the framework I use to define, evaluate, and scale high-impact experimentation.
Defining high-impact experimentation: NAV
To make experimentation work at scale, you need a clear view of what "good" looks like. That's why I developed NAV: a simple but powerful framework to evaluate the overall impact of your experimentation program and uncover the right levers to improve it.
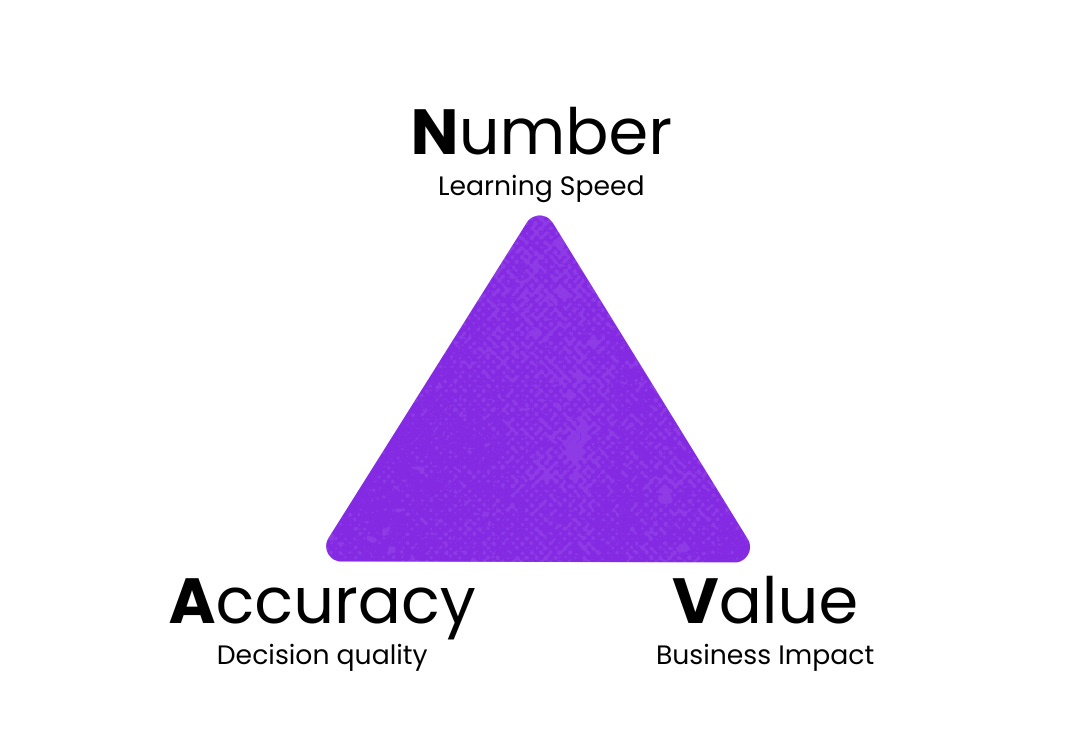
NAV breaks the impact of an experimentation program into three key drivers:
Number, Accuracy, and Value
Each lever represents one of the core drivers of experimentation impact. Pull them all in the right direction, and you get a compounding, organisation-wide learning engine.
Let’s break them down.
Number
How frequently, broadly, and operationally experiments are run: the pace and pervasiveness of learning across the business.
Number reflects how much useful experimentation is actually happening across teams, domains, and time. It covers factors like how quickly tests move from idea to launch, how much of the product surface is being explored, and how often customers experience change.
This matters because experimentation is a compounding process. The more frequently and broadly you run good tests, the faster your organisation learns and adapts. If testing is slow, siloed, or limited to narrow areas, growth stalls; not because of poor decisions, but because too few decisions are being tested in the first place.
Accuracy
How trustworthy, interpretable, and aligned experiment results are: ensuring that decisions based on experiments are sound.
Accuracy reflects how well your experiments are designed, analysed, and interpreted. It captures the clarity and rigour of your process from hypothesis to stats, to communication, and how well that process aligns with business reality.
This matters because poor Accuracy erodes trust and misleads decision-makers. Even with high test volume, if the underlying insights are shaky or misread, the program becomes noise or, worse, dangerous. High-accuracy programs don’t just produce “results”; they produce decisions people can stand behind.
Value
The extent to which experimentation drives real outcomes, shapes decisions, and compounds learning over time.
Value reflects the impact experimentation has on the business and not just whether results exist, but whether they’re used, whether they change outcomes, and whether they shape strategy over time.
This matters because testing is a means to an end. If nobody’s using the insights, or the business isn’t changing as a result, you don’t have an experimentation program. You have a reporting engine. High-Value programs are the ones that drive decisions, spark investment, and create momentum at every level of the organisation.
Want to know where your program stands?
You can now take a quick self-serve NAV assessment on my site:
👉 drsimonj.com/nav-survey
It only takes 3–5 minutes to complete.
Once you’re done, I’ll send you a personalised NAV assessment — including where you sit compared to world-class teams, and where the biggest opportunities for growth might be.
If you’re serious about scaling impact, this is a great place to start.
What’s next
NAV isn’t just a framework. It’s how I define high-impact experimentation and how I guide teams from “more testing” to real business impact.
So you can expect this newsletter to be packed with:
Deep dives into moving each NAV lever and its sub-facets
Real-world examples of high-impact programs (and how they got there)
A growing library of tools to plan, run, and scale better experiments
Tactical guides on moving from “test team” to “growth engine”
Behind-the-scenes breakdowns of how I assess and advise teams using NAV
And much more!
If this resonated, please share it with a team that could use a better compass.
Until next time 🙌
– Simon
Helping businesses scale high-impact experimentation
www.drsimonj.com
Other useful resources by DrSimonJ 🎉
🧮 The Experimenter’s Power Calculator to quickly plan high-quality experiments
📚The Experimenter’s Dictionary to find practical definitions and resources
🗞️ The Experimenter’s Advantage Newsletter for more of these in your inbox
✅ The NAV Benchmark survey to evaluate the impact of your program